
При запуске нескольких контейнеров Docker, будь то на одном сервере, в кластере Kubernetes или в Docker Swarm, очень важно иметь возможность отслеживать использование их ресурсов.
Вот где на помощь приходит cAdvisor . Он предоставляет полезные метрики для построения панелей мониторинга с использованием Grafana и Prometheus:
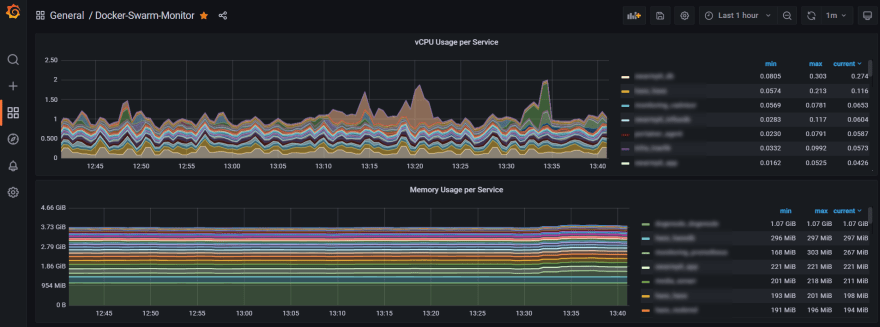
Но есть одна большая проблема: настройки cAdvisor по умолчанию .
Следствием использования конфигурации по умолчанию является очень высокая загрузка ЦП. Особенно это заметно на маломощных устройствах, таких как Raspberry Pi из кластера на графике выше.
cAdvisor использует больше ЦП, чем контейнеры, за которыми он следит! 😭
Исправление
К счастью, это довольно просто. Наибольшее влияние оказывают следующие параметры:
- housekeeping_interval
- только докер
- отключить_метрики
Подробное объяснение каждого можно найти здесь .
Пример Swarm с компоновкой Docker
Ниже я определяю housekeeping_interval30 секунд, устанавливаю значение docker_onlyи trueотключаю метрики, которые мне не интересны, используя disable_metrics.
ПРИМЕЧАНИЕ . Имейте в виду, что я использую версию cAdvisor для ARM, соответственно измените изображение/тег.
version: '3.4'
services:
cadvisor:
image: zcube/cadvisor:latest
ports:
- published: 9102
target: 9102
mode: host
command:
- "--port=9102"
- "--housekeeping_interval=30s"
- "--docker_only=true"
- "--disable_metrics=percpu,sched,tcp,udp,disk,diskIO,accelerator,hugetlb,referenced_memory,cpu_topology,resctrl"
volumes:
- /var/lib/docker/:/var/lib/docker:ro
- /dev/disk/:/dev/disk:ro
- /sys:/sys:ro
- /var/run:/var/run:ro
- /:/rootfs:ro
- /sys/fs/cgroup:/cgroup:ro
- /etc/machine-id:/etc/machine-id:ro
- /etc/localtime:/etc/localtime:ro
deploy:
mode: global
update_config:
order: stop-first
resources:
reservations:
memory: 80M
healthcheck:
test: wget --quiet --tries=1 --spider http://localhost:9102/healthz || exit 1
interval: 15s
timeout: 15s
retries: 5
start_period: 30sЭто помогло?
Проверь это:
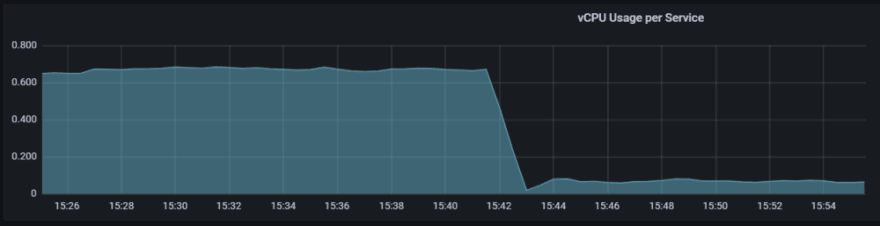
Уверен, вы догадываетесь, в какое время сработали новые настройки 😏. С 0,68 ВЦП до 0,08 ВЦП!
Совсем неплохо.



